















Summary
What Loki does
Turn a single photo into a moving portrait that copies expressions and head pose from a driver video — while staying the same person.
What makes it different
Don't stack more modules — replace the input. Pose and expression come from a parametric face model, already separated from identity.
Why it matters
43% fewer parameters · 1,496× less training video vs. SOTA. Cross-identity for free. Leads on pose- and expression-following.
How many clips did each model train on?
Every gauge uses the same scale (0 to 220k clips). Lower is better. Loki sits firmly in the green while the biggest baselines pin into amber and red.
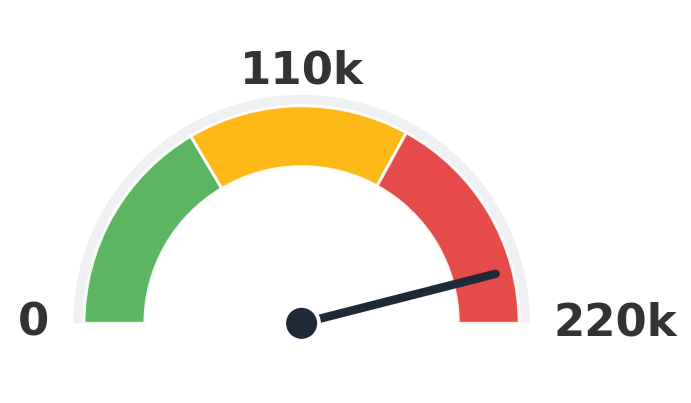
HunyuanPortrait
202,500 clips
19.0× Loki
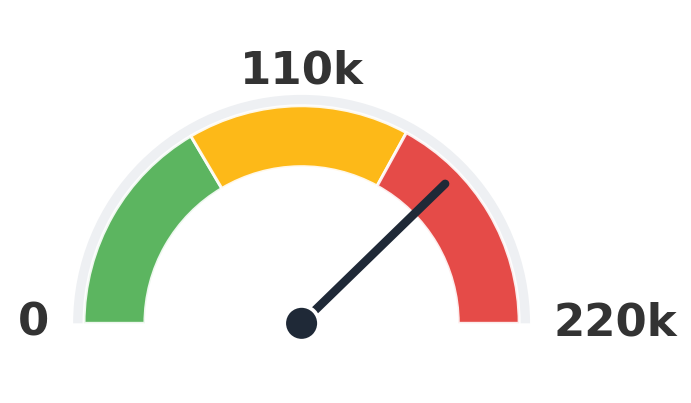
EchoMimic
166,000 clips
15.6× Loki
Ours
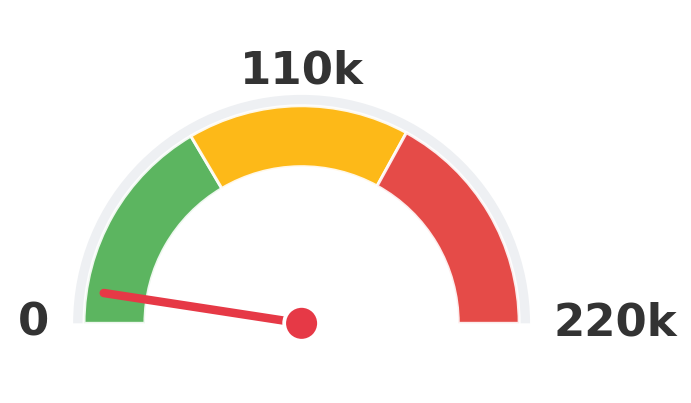
Loki
10,650 clips
1×
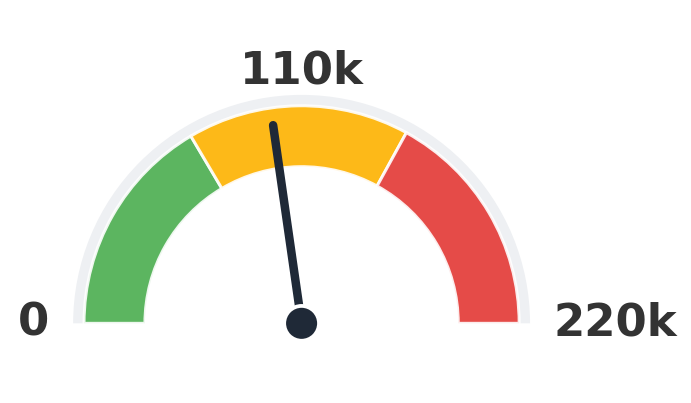
SadTalker
100,000 clips
9.4× Loki
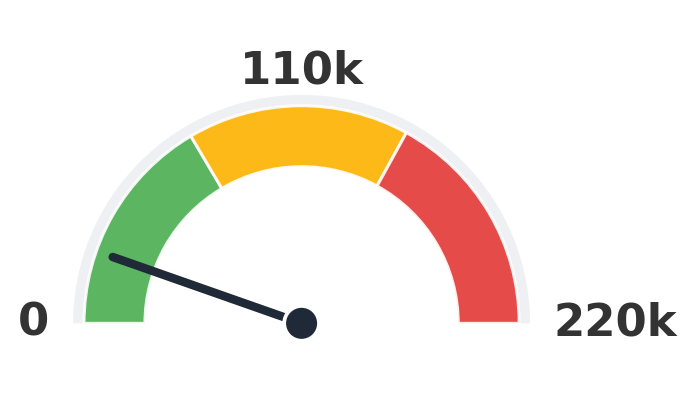
X-Portrait
23,650 clips
2.2× Loki
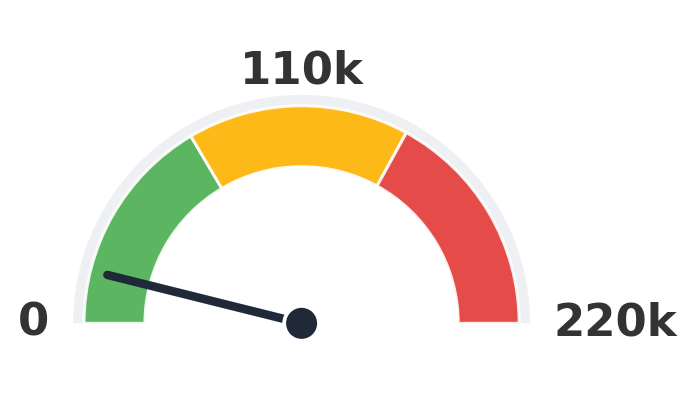
AniTalker
17,108 clips
1.6× Loki
Numbers are the upper-bound training-clip count reported by each method (paper Table 1).
Loki's Catalogue
A reel of Loki outputs across identities and driving clips. Step through with the arrows.
Inputs
Output
Reference

Driver


Reference
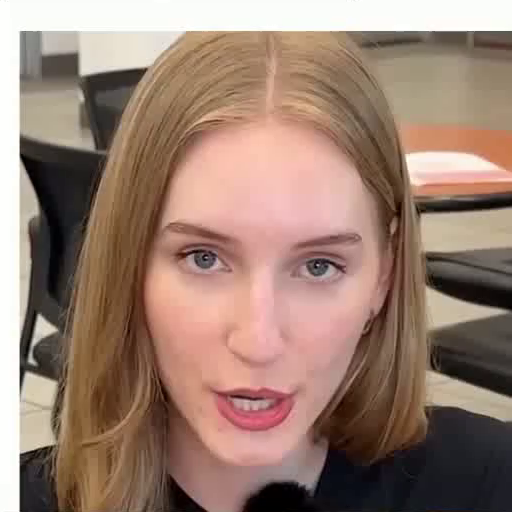
Driver

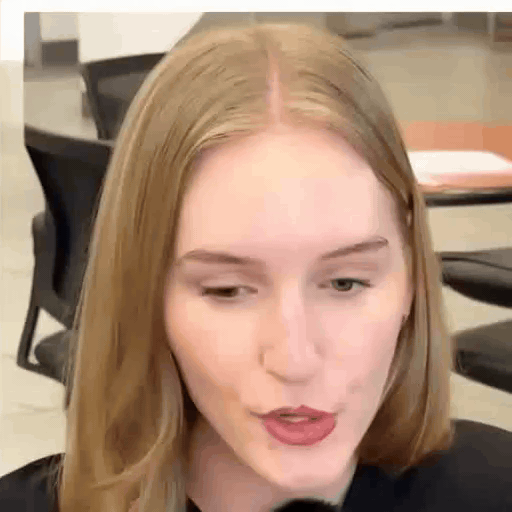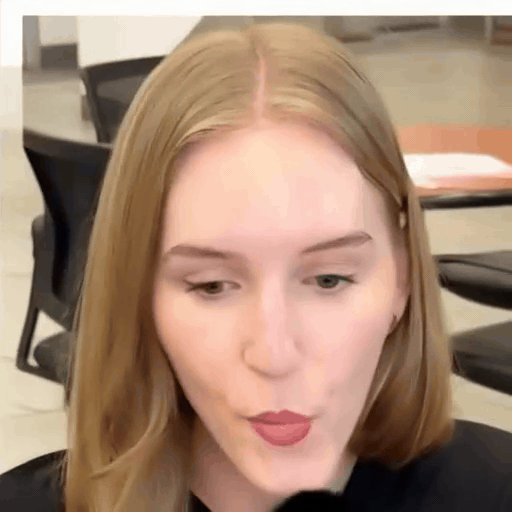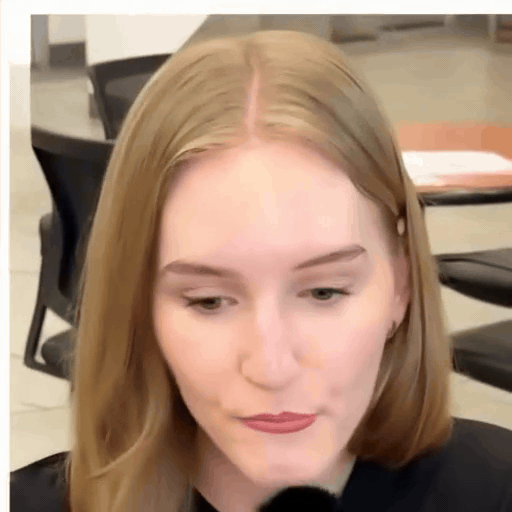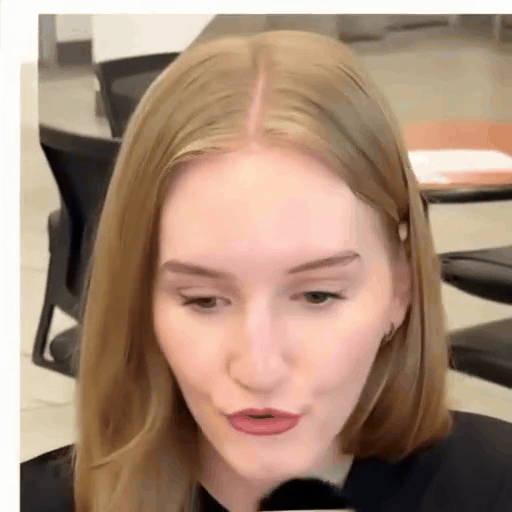
Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Reference

Driver


Comparison with SOTA
One row per sample. Reference identity and Driver motion on the left; Loki followed by every baseline on the right. Audio-driven baselines (EchoMimic, AniTalker, SadTalker) take reference + audio as input — we show the driver video for visual consistency with the video-driven baselines; the audio is synced to that driver clip.
Inputs
Ours (Loki)
X-Portrait
HunyuanPortrait
EchoMimic
AniTalker
SadTalker
Reference

Driver






Reference

Driver

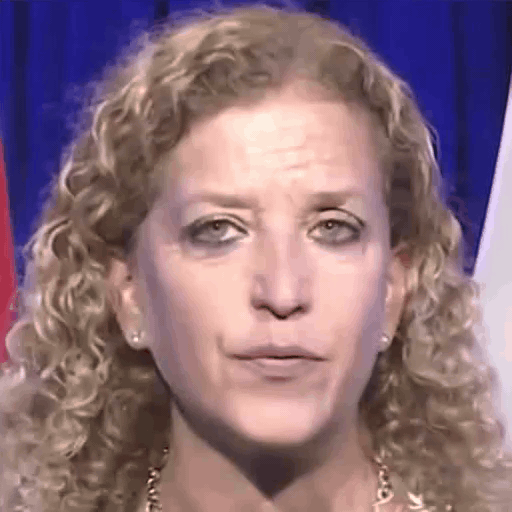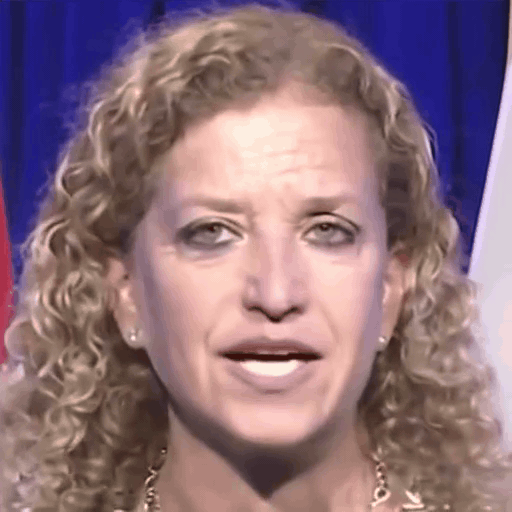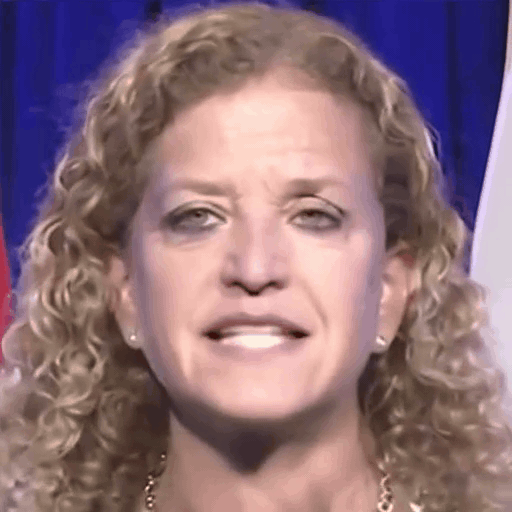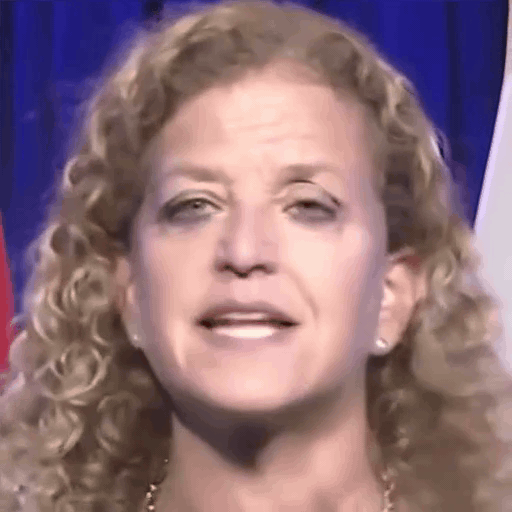
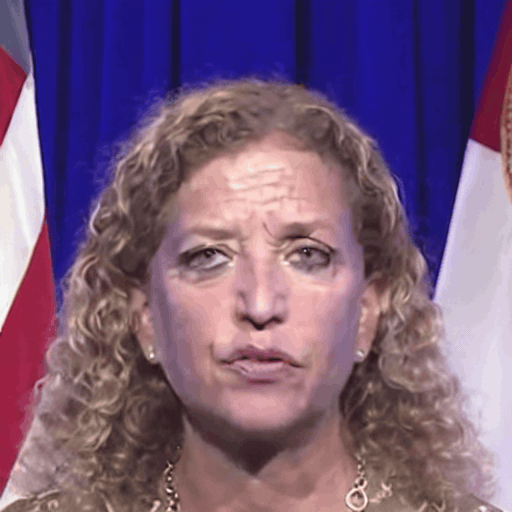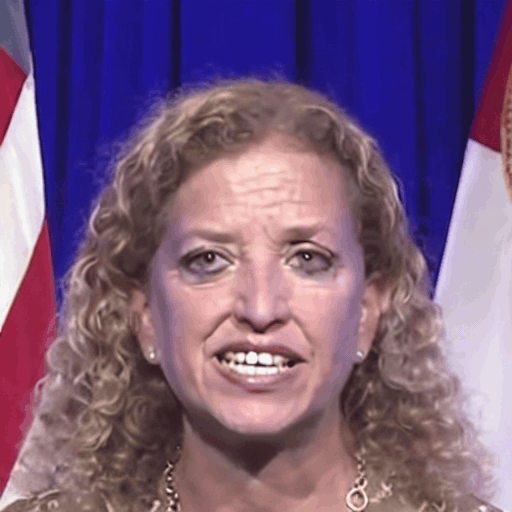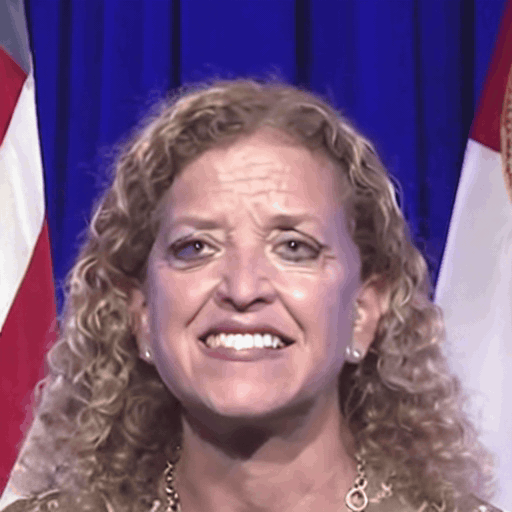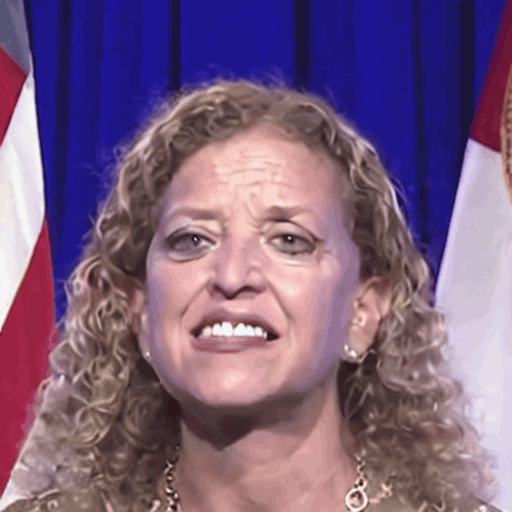
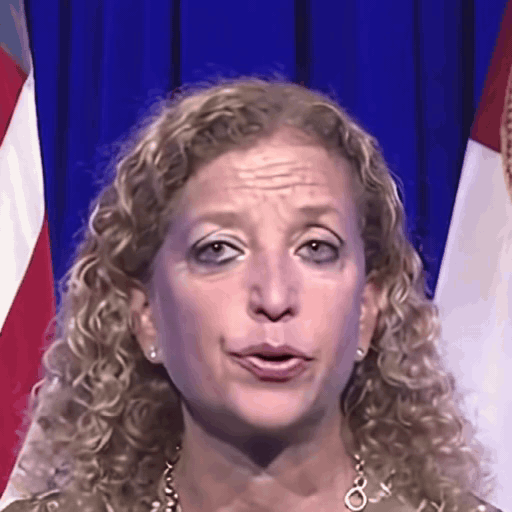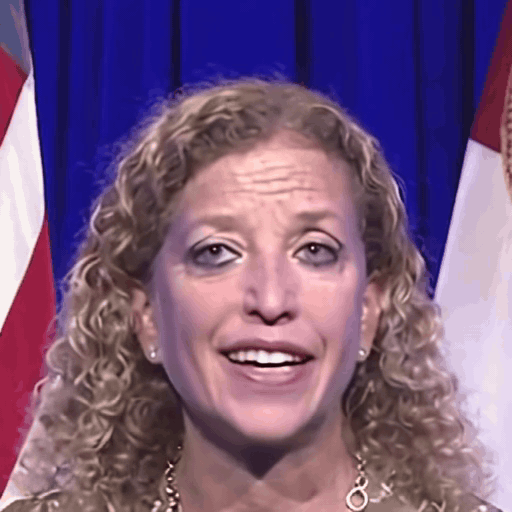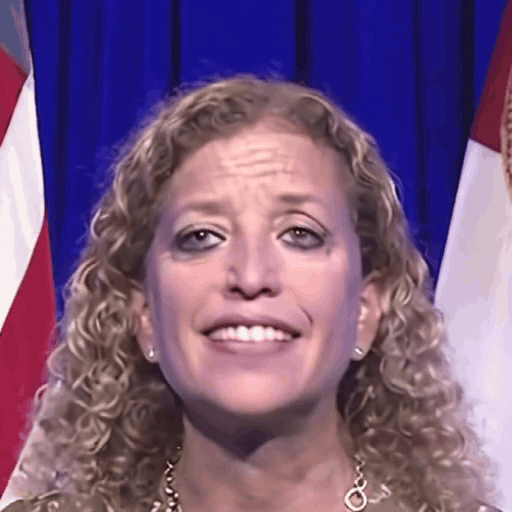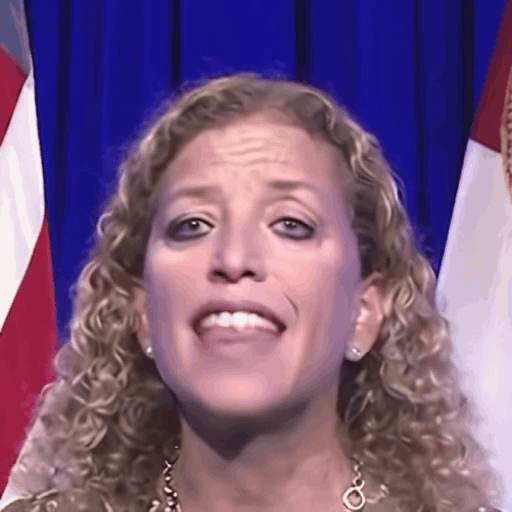
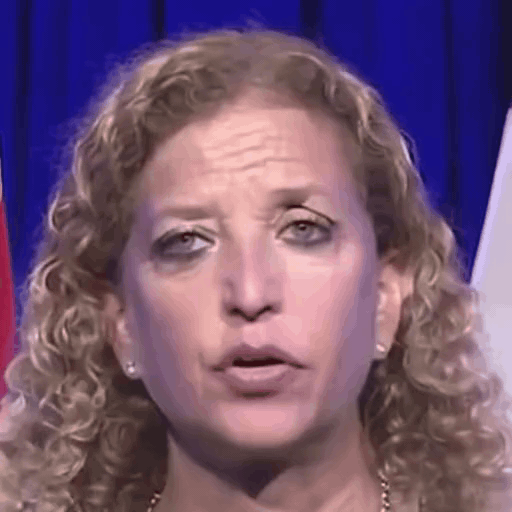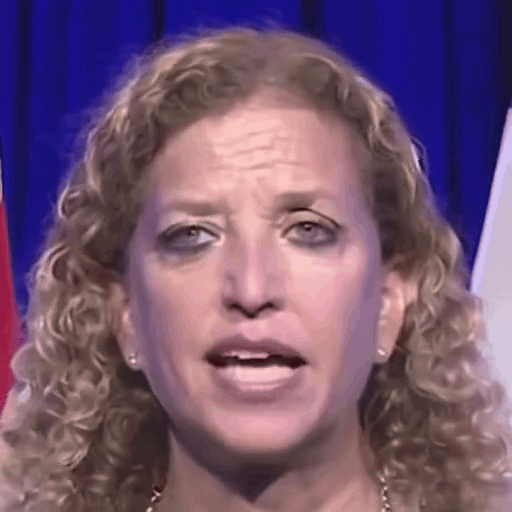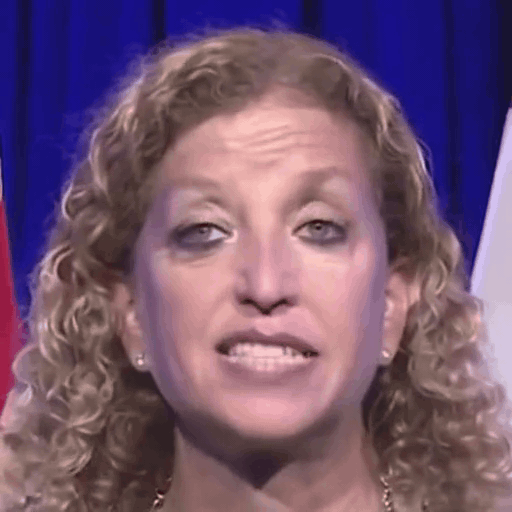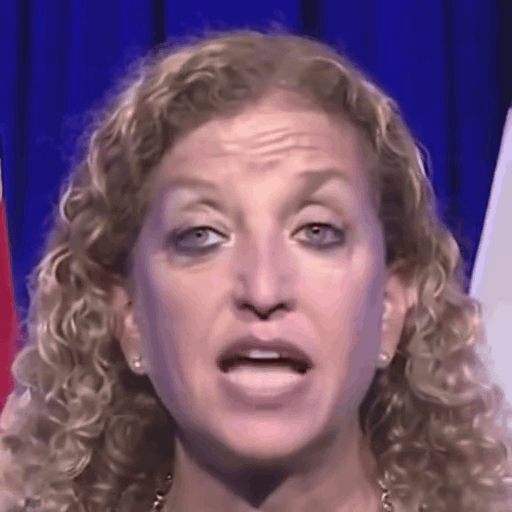

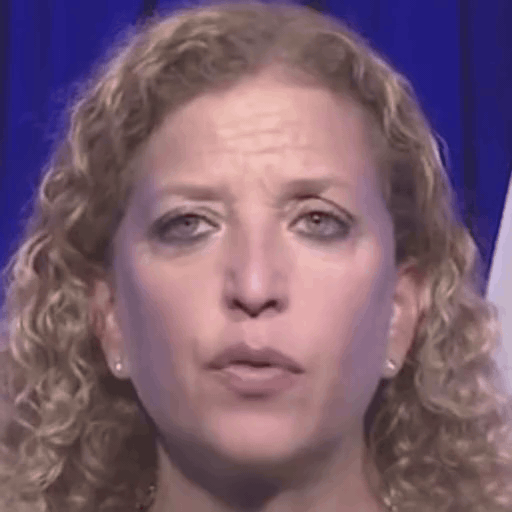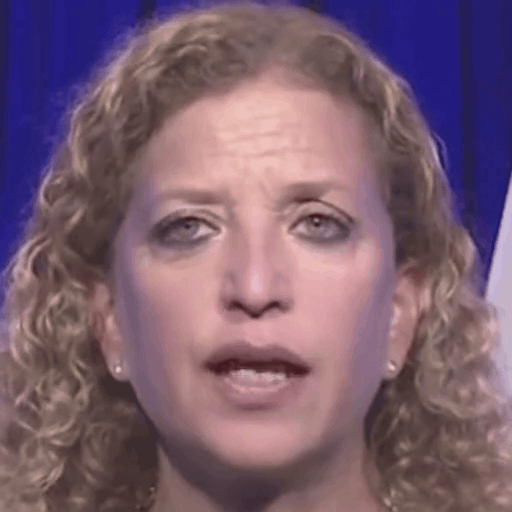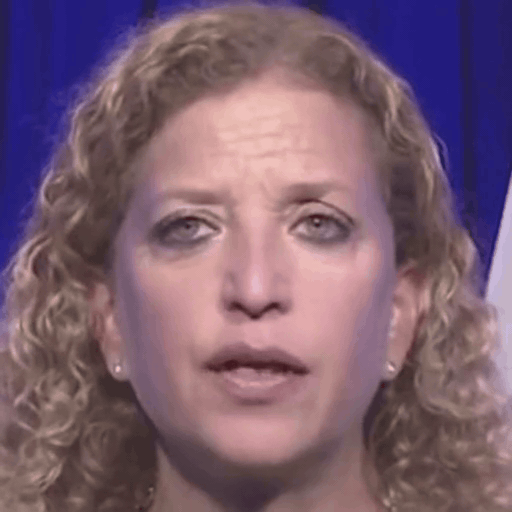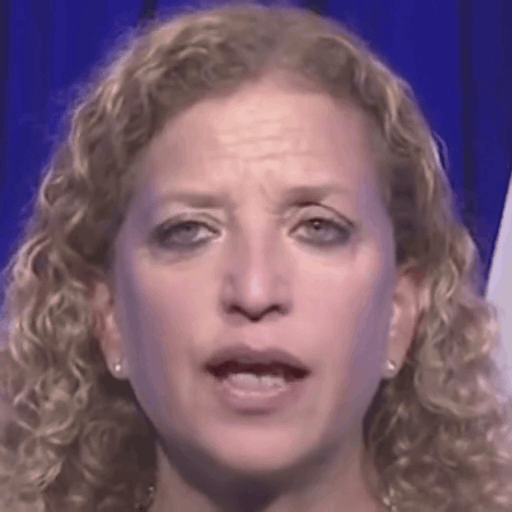
Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver







Reference

Driver


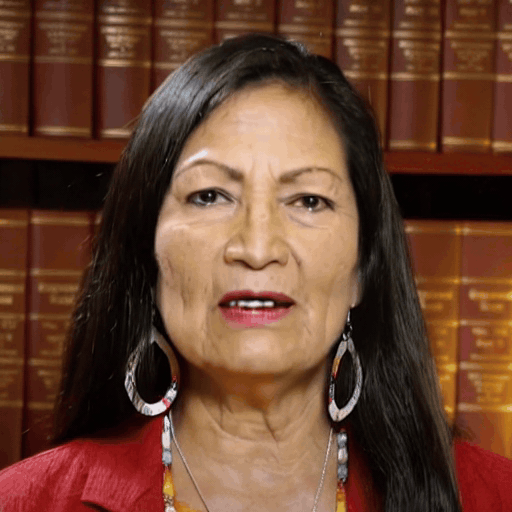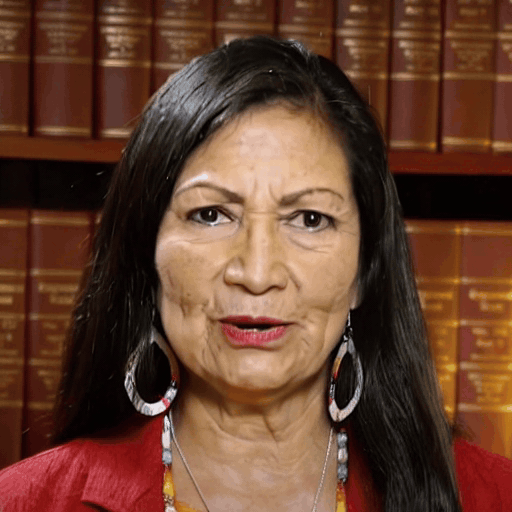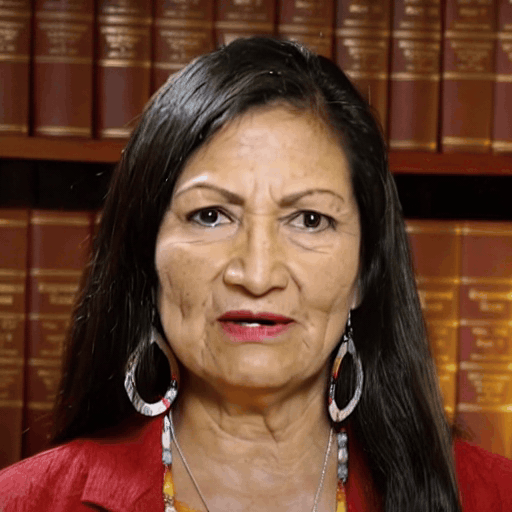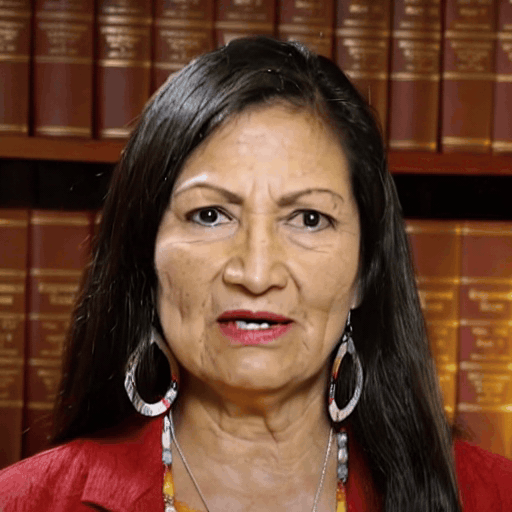
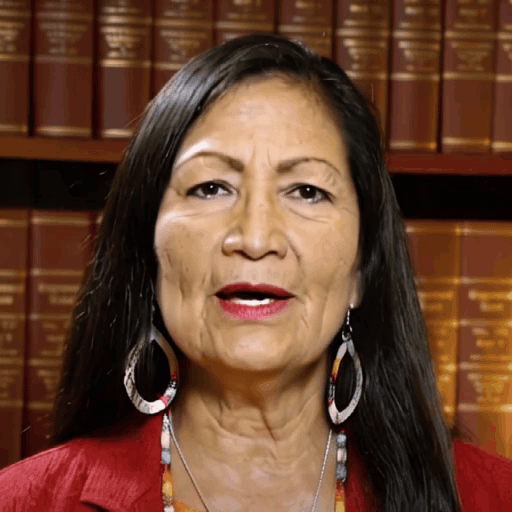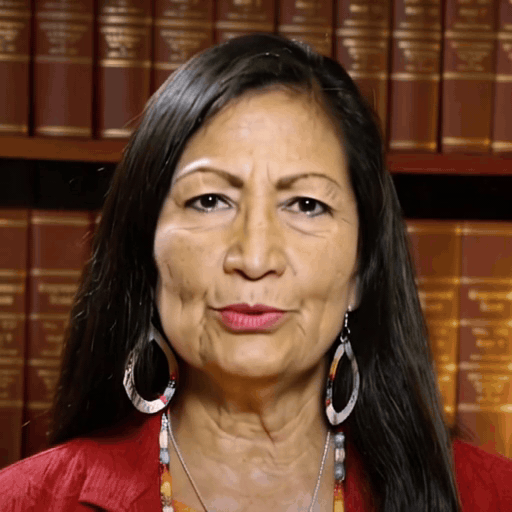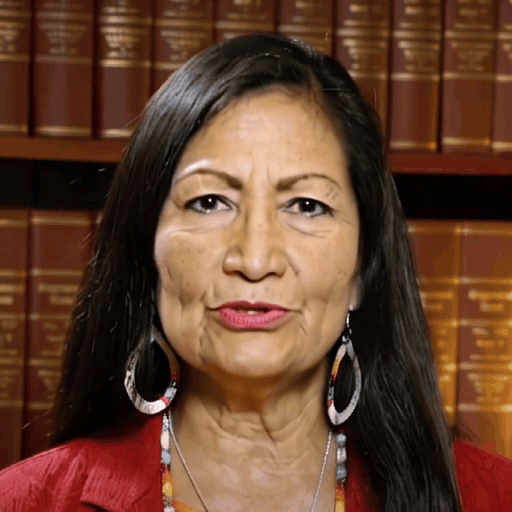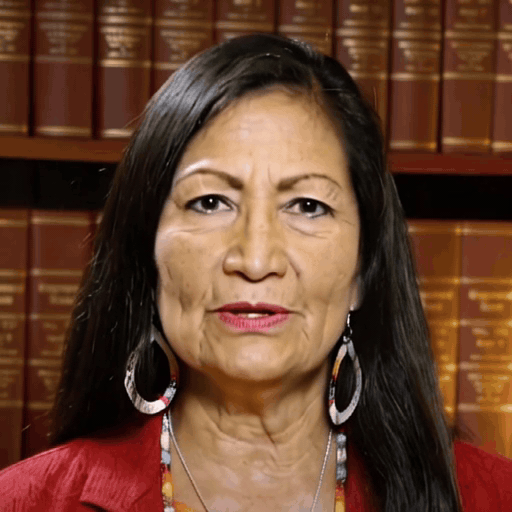



Reference

Driver







